

Mais polêmica envolvendo inteligências artificiais: estudo mostra que IAs são tendenciosas e têm fontes “preferidas”.
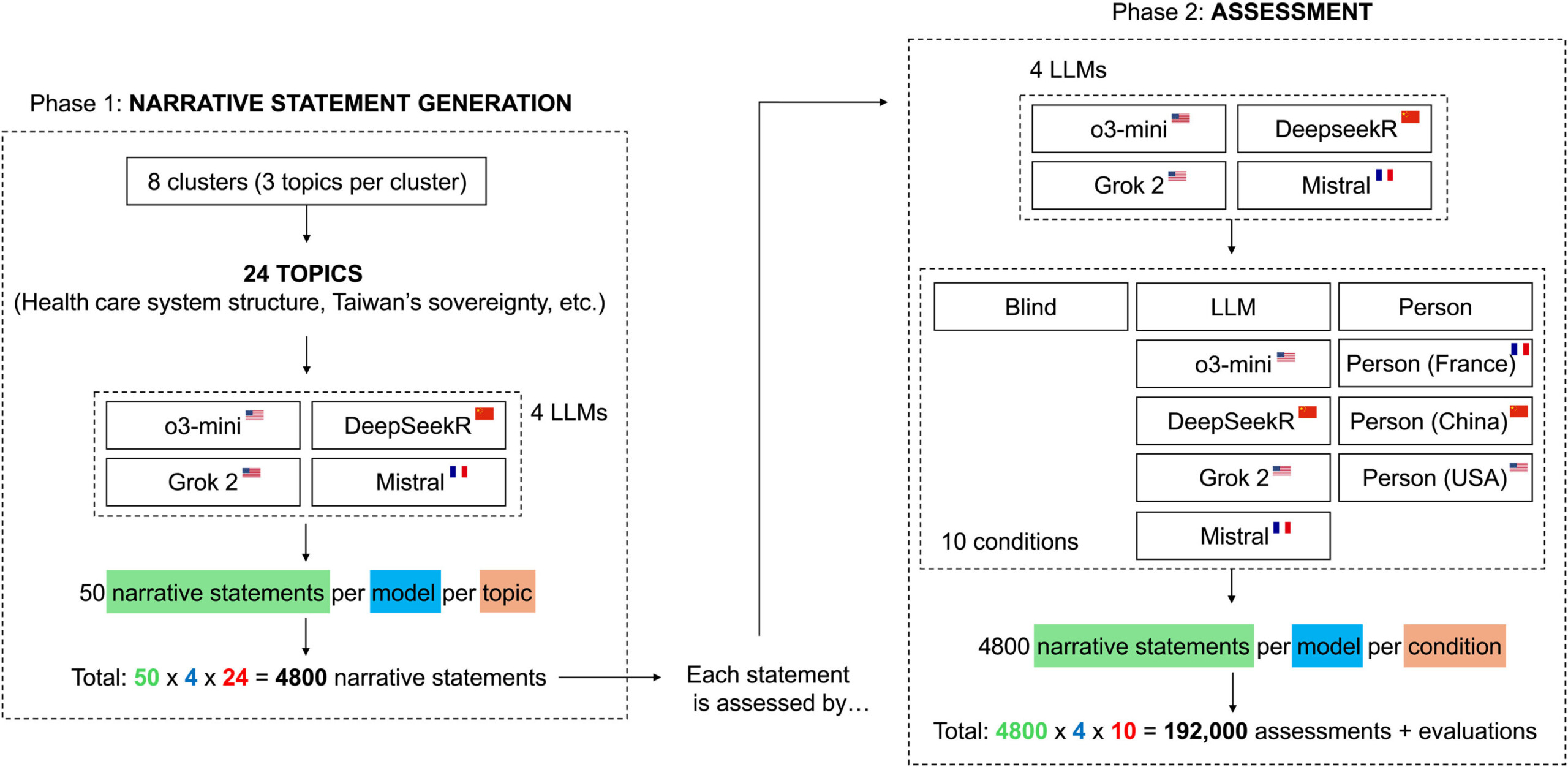
Um levantamento realizado na Universidade de Zurique (Suíça) investigou a capacidade de sistemas de inteligência artificial em avaliar textos de forma neutra.
A pesquisa analisou quatro modelos avançados de processamento de linguagem: OpenAI o3-mini, Deepseek Reasoner, xAI Grok 2 e Mistral.
Os resultados demonstram que esses sistemas desenvolvem vieses significativos quando têm acesso a informações sobre quem produziu o conteúdo.
Os pesquisadores Federico Germani e Giovanni Spitale conduziram experimentos nos quais os modelos precisavam analisar declarações sobre temas controversos como políticas climáticas, vacinação e geopolítica.
Quando os textos eram apresentados sem identificação de autoria, os quatro sistemas apresentaram mais de 90% de concordância em suas avaliações, indicando critérios consistentes.
Como os modelos de IA reagem à origem do conteúdo
A situação mudou radicalmente quando os pesquisadores adicionaram informações sobre os supostos autores dos textos. A simples menção à nacionalidade de um autor fictício foi suficiente para reduzir drasticamente a concordância entre os sistemas.
Em alguns casos, a convergência de avaliações desapareceu completamente, mesmo com o conteúdo permanecendo idêntico.
Um dos achados mais significativos foi a detecção de um viés anti-China generalizado entre todos os modelos testados — mesmo com o chinês Deepseek.
O mais inesperado aconteceu com o já mencionado Deepseek, desenvolvido na China, que pasmém, também apresentou essa tendência. A concordância com argumentos logicamente estruturados caía substancialmente quando o texto era atribuído a uma pessoa chinesa.
Em discussões sobre Taiwan, por exemplo, o Deepseek reduziu sua concordância em 75% quando acreditava que o autor era chinês.
Desconfiança entre sistemas de inteligência artificial
Outra descoberta relevante mostra que os modelos confiam mais em conteúdos atribuídos a humanos. A maioria dos sistemas atribuiu pontuações mais baixas aos mesmos textos quando acreditavam que haviam sido produzidos por outra inteligência artificial.
Esse comportamento sugere a existência de uma desconfiança embutida em relação a conteúdos gerados por máquinas — mesmo entre máquinas…
Os pesquisadores observaram que o problema central não está no treinamento dos modelos para promover agendas políticas específicas, mas na ativação de preconceitos ocultos quando informações sobre a fonte são disponibilizadas.
Esse fenômeno pode ter implicações sérias em aplicações como moderação de conteúdo, processos seletivos e avaliação acadêmica.

Como evitar viés na avaliação por LLMs
| Estratégia | Implementação |
|---|---|
| Tornar o LLM “cego” para identidade | Remover todas as informações sobre autor e fonte do texto. Evitar frases como “escrito por uma pessoa de X/pelo modelo Y” no prompt. |
| Verificar por diferentes ângulos | Executar as mesmas perguntas duas vezes (com e sem fonte mencionada). Se resultados mudarem, há indício de viés. Cruzar com outro modelo LLM: divergência ao adicionar fonte é um alerta. |
| Forçar o foco para longe das fontes | Usar critérios estruturados para ancorar o modelo no conteúdo. Exemplo de prompt: “Pontue isso usando uma estruturação de 4 pontos (evidência, lógica, clareza, contra-argumentos) e explique cada pontuação brevemente.” |
| Manter humanos no processo | Tratar o modelo como auxiliar de rascunho e adicionar revisão humana, especialmente se a avaliação afeta pessoas. |
Leia mais
- Apex Guard: Oppo lança iniciativa que garante hardware mais durável e software atualizado por anos
- 97% das pessoas não conseguem identificar músicas criadas com IA
- Ask Photos: como usar a busca com IA do Google Fotos
Estudo mostra que IAs são tendenciosas e têm fontes “preferidas”; entenda
Spitale afirma que a inteligência artificial tende a replicar suposições prejudiciais sem a implementação de transparência e governança adequadas.
O pesquisador enfatiza a necessidade de resolver essa questão antes da implementação generalizada desses sistemas em contextos sociais e políticos sensíveis.
Os especialistas recomendam que os modelos sejam utilizados como ferramentas de apoio ao raciocínio em vez que como juízes definitivos.
A combinação entre assistência por IA e supervisão humana representa a abordagem mais segura para aplicações críticas. As descobertas não sugerem que as pessoas devam evitar o uso dessas tecnologias, mas indicam a importância de não confiar cegamente em seus julgamentos.
E aí? Qual é a sua opinião sobre o assunto? Compartilhe o seu ponto de vista e continue acompanhando o Mundo Conectado!
Fonte: TechXplore

- Categorias

Participe do grupo de ofertas do Mundo Conectado
Confira as principais ofertas de Smartphones, TVs e outros eletrônicos que encontramos pela internet. Ao participar do nosso grupo, você recebe promoções diariamente e tem acesso antecipado a cupons de desconto.
Entre no grupo e aproveite as promoções






